Sentiment analysis is the process of identifying and extracting subjective information from text, such as opinions and emotions.
There are several methods that can be used for sentiment analysis, including:
- Lexicon-based methods: In this method, sentiment scores are assigned to words based on their dictionary meanings. The sentiment scores are then aggregated to produce an overall sentiment score for a piece of text.
The different approaches to lexicon-based approach are:
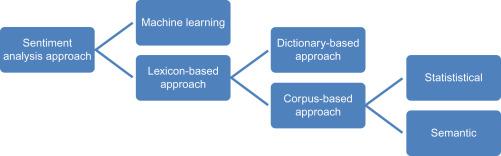
Dictionary-based approach
In this approach, a dictionary is created by taking a few words initially. Then an online dictionary, thesaurus or WordNet can be used to expand that dictionary by incorporating synonyms and antonyms of those words. The dictionary is expanded till no new words can be added to that dictionary. The dictionary can be refined by manual inspection.
Corpus-based approach
This finds sentiment orientation of context-specific words. The two methods of this approach are:
- Statistical approach: The words which show erratic behavior in positive behavior are considered to have positive polarity. If they show negative recurrence in negative text they have negative polarity. If the frequency is equal in both positive and negative text then the word has neutral polarity.
- Semantic approach: This approach assigns sentiment values to words and the words which are semantically closer to those words; this can be done by finding synonyms and antonyms with respect to that word.
- Machine learning-based methods: In this method, a machine learning algorithm is trained on a labeled dataset to predict the sentiment of a given piece of text. The algorithm can then be used to classify new text as positive, negative, or neutral.
- Hybrid methods: These methods combine lexicon-based and machine learning-based methods to improve the accuracy of sentiment analysis.
- Rule-based methods: In this method, a set of rules are defined to identify sentiment in a piece of text. The rules may be based on linguistic rules or domain-specific rules. The choice of method depends on the specific requirements of the analysis, the quality and quantity of data, and the available resources.
Steps in Rule-based approach:
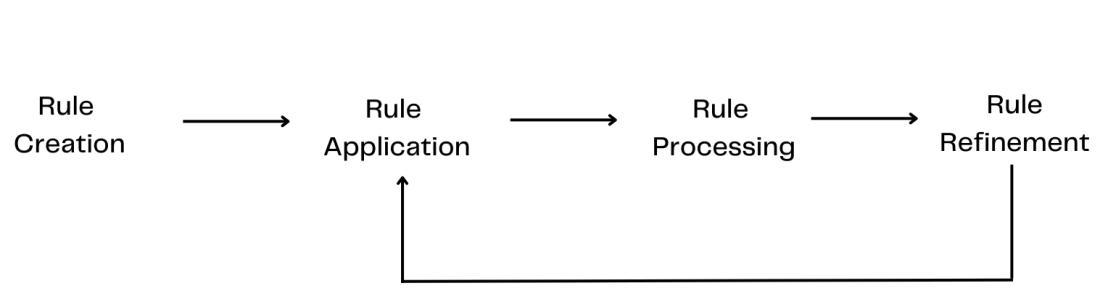
- Rule Creation: Based on the desired tasks, domain-specific linguistic rules are created such as grammar rules, syntax patterns, semantic rules or regular expressions.
- Rule Application: The predefined rules are applied to the inputted data to capture matched patterns.
- Rule Processing: The text data is processed in accordance with the results of the matched rules to extract information, make decisions or other tasks.
- Rule refinement: The created rules are iteratively refined by repetitive processing to improve accuracy and performance. Based on previous feedback, the rules are modified and updated when needed.