- Logistic regression is one of the most popular Machine Learning algorithms, which comes under the Supervised Learning technique. It is used for predicting the categorical dependent variable using a given set of independent variables.
- Logistic regression predicts the output of a categorical dependent variable. Therefore the outcome must be a categorical or discrete value. It can be either Yes or No, 0 or 1, true or False, etc. but instead of giving the exact value as 0 and 1, it gives the probabilistic values which lie between 0 and 1.
- Logistic Regression is much similar to the Linear Regression except that how they are used. Linear Regression is used for solving Regression problems, whereas Logistic regression is used for solving the classification problems.
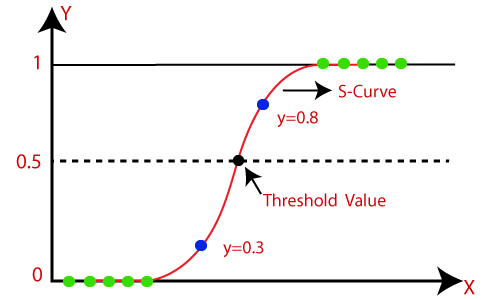
- In Logistic regression, instead of fitting a regression line, we fit an “S” shaped logistic function, which predicts two maximum values (0 or 1).
- The curve from the logistic function indicates the likelihood of something such as whether the cells are cancerous or not, a mouse is obese or not based on its weight, etc.
- Logistic Regression is a significant machine learning algorithm because it has the ability to provide probabilities and classify new data using continuous and discrete datasets.
- Logistic Regression can be used to classify the observations using different types of data and can easily determine the most effective variables used for the classification. The below image is showing the logistic function:
Why do we use Logistic Regression rather than Linear Regression?
- Logistic regression is only used when our dependent variable is binary and in linear regression this dependent variable is continuous.
- The second problem is that if we add an outlier in our dataset, the best fit line in linear regression shifts to fit that point.
- Now, if we use linear regression to find the best fit line which aims at minimizing the distance between the predicted value and actual value, the line will be like this:
- Here the threshold value is 0.5, which means if the value of h(x) is greater than 0.5 then we predict malignant tumor (1) and if it is less than 0.5 then we predict benign tumor (0).
- Everything seems okay here but now let’s change it a bit, we add some outliers in our dataset, now this best fit line will shift to that point. Hence the line will be somewhat like this:
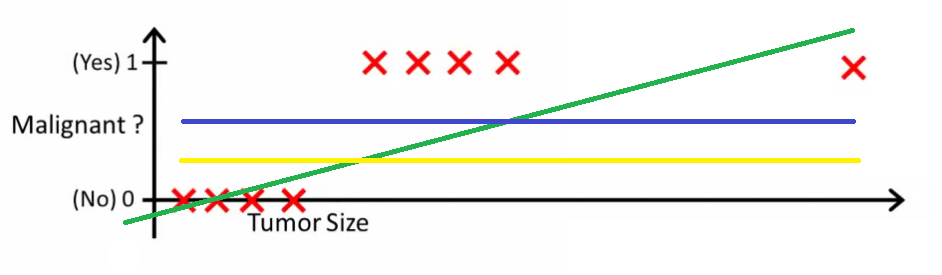
- The blue line represents the old threshold and the yellow line represents the new threshold which is maybe 0.2 here.
- To keep our predictions right we had to lower our threshold value. Hence we can say that linear regression is prone to outliers.
- Now here if h(x) is greater than 0.2 then only this regression will give correct outputs.
- Another problem with linear regression is that the predicted values may be out of range.
- We know that probability can be between 0 and 1, but if we use linear regression this probability may exceed 1 or go below 0.
- To overcome these problems we use Logistic Regression, which converts this straight best fit line in linear regression to an S-curve using the sigmoid function, which will always give values between 0 and 1.
Ajink Gupta Answered question