ML QuestionPaper Solution May 2023 – AI-DS/ML
Table of Contents
Q.1 Solve any Four
A. What is Machine Learning? What are the steps in developing a machine learning application? [05]
Machine Learning (ML) is a subset of artificial intelligence (AI) that focuses on enabling machines to learn from data without explicit programming. It allows computers to automatically learn and improve from experience, uncover patterns in data, and make predictions or decisions based on that data.
Steps in Developing a Machine Learning Application:
- Collect Data: Gather relevant data from various sources.
- Prepare Input Data: Clean, preprocess, and format the collected data for analysis.
- Analyze Input Data: Explore and understand the data to identify patterns, trends, and relationships.
- Train Algorithm: Select and train the machine learning algorithm(s) on the prepared data.
- Test Algorithm: Evaluate the performance of the trained algorithm(s) using test data to ensure accuracy and generalization.
- Use Algorithm: Deploy the trained algorithm(s) for making predictions or decisions in real-world applications.
- Predict and Revise: Utilize the algorithm(s) to generate predictions or outcomes, and revisit the model periodically for updates and improvements based on new data or feedback.
B. Differentiate between supervised and unsupervised learning. [05]
| Supervised Learning | Unsupervised Learning | |
|---|---|---|
| Input Data | Uses Known and Labeled Data as input | Uses Unknown Data as input |
| Computational Complexity | Less Computational Complexity | More Computational Complex |
| Real-Time | Uses off-line analysis | Uses Real-Time Analysis of Data |
| Number of Classes | The number of Classes is known | The number of Classes is not known |
| Accuracy of Results | Accurate and Reliable Results | Moderate Accurate and Reliable Results |
| Output data | The desired output is given. | The desired, output is not given. |
| Model | In supervised learning it is not possible to learn larger and more complex models than in unsupervised learning | In unsupervised learning it is possible to learn larger and more complex models than in supervised learning |
| Training data | In supervised learning training data is used to infer model | In unsupervised learning training data is not used. |
| Another name | Supervised learning is also called classification. | Unsupervised learning is also called clustering. |
| Test of model | We can test our model. | We can not test our model. |
| Example | Optical Character Recognition | Find a face in an image. |
C. Draw and explain biological neural networks and compare them with artificial neural networks. [05]
The biological neural network is also composed of several processing pieces known as neurons that are linked together via synapses. These neurons accept either external input or the results of other neurons. The generated output from the individual neurons propagates its effect on the entire network to the last layer, where the results can be displayed to the outside world.
Every synapse has a processing value and weight recognized during network training. The performance and potency of the network fully depend on the neuron numbers in the network, how they are connected to each other (i.e., topology), and the weights assigned to every synapse.
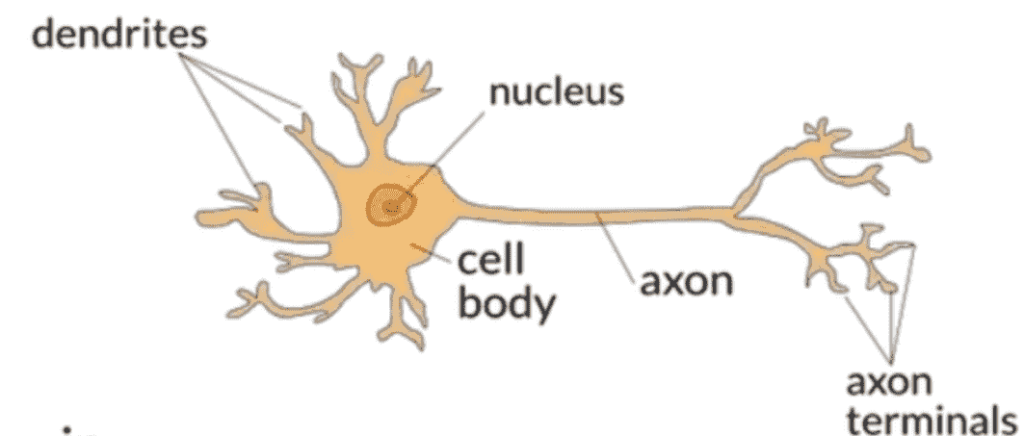
- Dendrite: Dendrites are branched extensions of a neuron that receive signals from other neurons or sensory receptors. They act like antennae, collecting incoming electrical and chemical signals and transmitting them towards the cell body.
- Axon: An axon is a long, slender projection of a neuron that carries electrical impulses away from the cell body toward other neurons, muscles, or glands. It’s like a cable transmitting signals over long distances.
- Nucleus: The nucleus is the central part of a cell that contains genetic material (DNA) and controls the cell’s activities. In neurons, the nucleus is located in the cell body.
- Cell Body (Soma): The cell body, also called the soma, is the main part of a neuron that contains the nucleus and other organelles essential for the cell’s functioning. It integrates incoming signals from dendrites and generates outgoing signals to the axon.
- Synapse: A synapse is a junction between two neurons or between a neuron and a target cell (such as a muscle or gland). It’s where the electrical signal from one neuron is transmitted to another cell through chemical or electrical signaling. Synapses are crucial for communication between neurons in the nervous system.
| Features | Artificial Neural Network | Biological Neural Network |
|---|---|---|
| Definition | It is the mathematical model which is mainly inspired by the biological neuron system in the human brain. | It is also composed of several processing pieces known as neurons that are linked together via synapses. |
| Processing | Its processing was sequential and centralized. | It processes the information in a parallel and distributive manner. |
| Size | It is small in size. | It is large in size. |
| Control Mechanism | Its control unit keeps track of all computer-related operations. | All processing is managed centrally. |
| Rate | It processes the information at a faster speed. | It processes the information at a slow speed. |
| Complexity | It cannot perform complex pattern recognition. | The large quantity and complexity of the connections allow the brain to perform complicated tasks. |
| Feedback | It doesn’t provide any feedback. | It provides feedback. |
| Fault tolerance | There is no fault tolerance. | It has fault tolerance. |
| Operating Environment | Its operating environment is well-defined and well-constrained | Its operating environment is poorly defined and unconstrained. |
| Memory | Its memory is separate from a processor, localized, and non-content addressable. | Its memory is integrated into the processor, distributed, and content-addressable. |
| Reliability | It is very vulnerable. | It is robust. |
| Learning | It has very accurate structures and formatted data. | They are tolerant to ambiguity. |
| Response time | Its response time is measured in milliseconds. | Its response time is measured in nanoseconds. |
D. Explain in detail the MP neuron model. [05]
The McCulloch-Pitts neural model, which was the earliest ANN model, has only two types of inputs — Excitatory and Inhibitory. The excitatory inputs have weights of positive magnitude and the inhibitory weights have weights of negative magnitude. The inputs of the McCulloch-Pitts neuron could be either 0 or 1. It has a threshold function as an activation function. So, the output signal yout is 1 if the input ysum is greater than or equal to a given threshold value, else 0. The diagrammatic representation of the model is as follows:
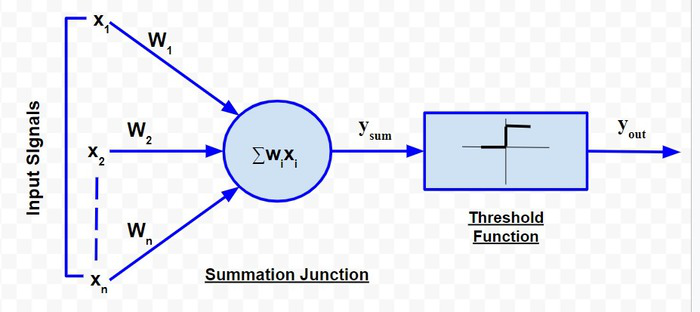
McCulloch-Pitts Model
Simple McCulloch-Pitts neurons can be used to design logical operations. For that purpose, the connection weights need to be correctly decided along with the threshold function (rather than the threshold value of the activation function). For better understanding purpose, let me consider an example:
John carries an umbrella if it is sunny or if it is raining. There are four given situations. I need to decide when John will carry the umbrella. The situations are as follows:
- First scenario: It is not raining, nor it is sunny
- Second scenario: It is not raining, but it is sunny
- Third scenario: It is raining, and it is not sunny
- Fourth scenario: It is raining as well as it is sunny
To analyse the situations using the McCulloch-Pitts neural model, I can consider the input signals as follows:
- X1: Is it raining?
- X2 : Is it sunny?
So, the value of both scenarios can be either 0 or 1. We can use the value of both weights X1 and X2 as 1 and a threshold function as 1. So, the neural network model will look like:
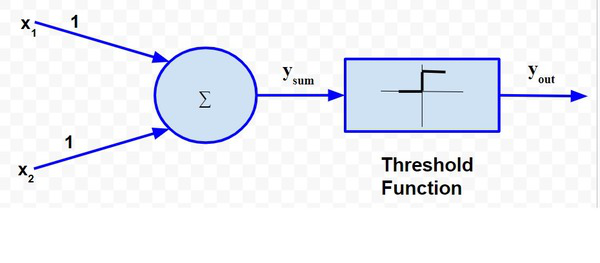
Truth Table for this case will be:
| Situation | x1 | x2 | ysum | yout |
| 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 1 | 1 | 1 |
| 3 | 1 | 0 | 1 | 1 |
| 4 | 1 | 1 | 2 | 1 |
So, I can say that,
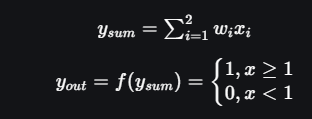
The truth table built with respect to the problem is depicted above. From the truth table, I can conclude that in the situations where the value of yout is 1, John needs to carry an umbrella. Hence, he will need to carry an umbrella in scenarios 2, 3 and 4.
https://www.geeksforgeeks.org/implementing-models-of-artificial-neural-network
E. Explain overfitting and underfitting with examples. [05]
Answer : https://www.doubtly.in/q/explain-overfitting-underfitting-examples/
Q.2
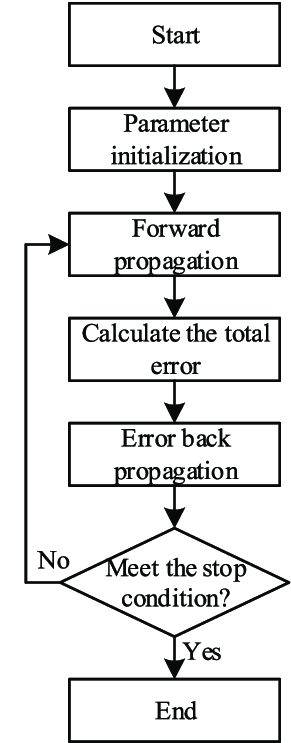
A. Draw a block diagram of the Error Back Propagation Algorithm and explain with a flowchart the Error Back Propagration concept . [10]
The Error Back Propagation Algorithm, commonly referred to as Backpropagation, is a fundamental algorithm used for training artificial neural networks. It is a supervised learning algorithm that aims to minimize the error between the predicted outputs and the actual outputs by adjusting the weights of the network.

- Neural Network Structure:
- Input Layer: Receives input features.
- Hidden Layers: Intermediate layers where computations are performed.
- Output Layer: Produces the final output.
- Weights and Biases: Parameters that the algorithm adjusts to minimize the error.
- Activation Function: A non-linear function (like Sigmoid, ReLU, Tanh) applied to the neuron’s output to introduce non-linearity into the model.
- Loss Function: Measures the difference between the predicted output and the actual output (e.g., Mean Squared Error, Cross-Entropy Loss).
Steps in Backpropagation
- Initialization: Randomly initialize weights and biases.
- Forward Propagation:
- Compute the output of each neuron from the input layer to the output layer.
- For each layer, apply the activation function to the weighted sum of inputs.
- Compute Loss: Calculate the error using the loss function.
- Backward Propagation:
- Compute the gradient of the loss function with respect to each weight by applying the chain rule of calculus.
- This involves:
- Output Layer: Calculate the gradient of the loss with respect to the output.
- Hidden Layers: Backpropagate the gradient to previous layers, updating the weights and biases.
- Update Weights:
- Adjust weights and biases using gradient descent or an optimization algorithm (like Adam, RMSprop).
- Update rule:
[
w = w – \eta \frac{\partial L}{\partial w}
]
where ( \eta ) is the learning rate, ( w ) is the weight, and ( \frac{\partial L}{\partial w} ) is the gradient of the loss with respect to the weight.
- Iterate: Repeat the forward and backward pass for a number of epochs or until convergence.
Practical Considerations
- Learning Rate: A critical hyperparameter that needs to be set properly. Too high can lead to divergence, too low can slow convergence.
- Overfitting: Use techniques like regularization (L1, L2), dropout, or early stopping to prevent overfitting.
- Gradient Vanishing/Exploding: Deep networks may suffer from these issues. Techniques like Batch Normalization, appropriate activation functions (ReLU), and gradient clipping help mitigate them.
B. The values of the independent variable ( X ) and the dependent variable ( Y ) are given below:
| X | Y |
| 0 | 2 |
| 1 | 3 |
| 2 | 5 |
| 3 | 4 |
| 4 | 6 |
Find the least square regression line ( Y = aX + b ). Estimate ( Y ) when the value of ( X ) equals 10. [10]
Answer : https://www.doubtly.in/q/values-independent-variable-dependent-variable/
Q.3
A. Diagonalize the matrix A
| 2 | 2 |
| 1 | 3 |
Solution : https://www.doubtly.in/q/diagonalize-matrix-2-2-1-3/
B. List out and explain the applications of SVD. [05]
Singular Value Decomposition (SVD) is a powerful matrix factorization technique with various applications across different domains. Here are some common applications of SVD:
- Dimensionality Reduction:
- SVD can be used for dimensionality reduction in datasets with high-dimensional features. By retaining only the top-k singular values and their corresponding singular vectors, SVD can approximate the original data matrix with reduced dimensions. This is particularly useful for tasks such as image compression, text mining, and recommender systems.
- Image Compression:
- In image processing, SVD can be applied to compress images while preserving important information. By decomposing the image matrix into its singular values and vectors, low-rank approximations can be generated, leading to significant compression without losing visual quality.
- Recommender Systems:
- SVD is widely used in collaborative filtering-based recommender systems to make personalized recommendations. By decomposing the user-item interaction matrix into latent factors (represented by singular vectors), SVD can capture underlying patterns in the data and predict users’ preferences for items they have not yet interacted with.
- Data Denoising:
- SVD can be used for denoising noisy data by filtering out the noise components. By retaining only the dominant singular values and their corresponding singular vectors, SVD can separate the signal from the noise, leading to cleaner data representations.
- Latent Semantic Analysis (LSA):
- In natural language processing (NLP), SVD is applied in Latent Semantic Analysis (LSA) to uncover hidden semantic structures in text documents. By decomposing the term-document matrix into latent topics, SVD enables document clustering, information retrieval, and text summarization.
- Face Recognition:
- SVD is used in facial recognition systems to extract important features from face images. By decomposing the face image matrix into its singular values and vectors, SVD can identify unique facial features and reduce the dimensionality of the face space, making it easier to compare and recognize faces.
- Principal Component Analysis (PCA):
- PCA is a dimensionality reduction technique closely related to SVD. PCA utilizes the eigenvectors of the covariance matrix of the data, which can be obtained through SVD. PCA is widely used for feature extraction, data visualization, and noise reduction in various applications.
- Signal Processing:
- SVD plays a crucial role in signal processing tasks such as noise reduction, channel equalization, and system identification. By decomposing the signal matrix into its singular values and vectors, SVD can reveal important signal characteristics and aid in signal reconstruction and analysis.
Overall, SVD is a versatile mathematical tool with numerous applications in diverse fields such as image processing, NLP, recommendation systems, and signal processing, enabling efficient data analysis, modeling, and representation.
C. Write a short note on the Expectation-Maximization algorithm. [05]
The Expectation-Maximization (EM) algorithm is defined as the combination of various unsupervised machine learning algorithms, which is used to determine the local maximum likelihood estimates (MLE) or maximum a posteriori estimates (MAP) for unobservable variables in statistical models. Further, it is a technique to find maximum likelihood estimation when the latent variables are present. It is also referred to as the latent variable model.
A latent variable model consists of both observable and unobservable variables where observable can be predicted while unobserved are inferred from the observed variable. These unobservable variables are known as latent variables.
Key Points:
- It is known as the latent variable model to determine MLE and MAP parameters for latent variables.
- It is used to predict values of parameters in instances where data is missing or unobservable for learning, and this is done until convergence of the values occurs.
EM Algorithm
The EM algorithm is the combination of various unsupervised ML algorithms, such as the k-means clustering algorithm. Being an iterative approach, it consists of two modes. In the first mode, we estimate the missing or latent variables. Hence it is referred to as the Expectation/estimation step (E-step). Further, the other mode is used to optimize the parameters of the models so that it can explain the data more clearly. The second mode is known as the maximization-step or M-step.
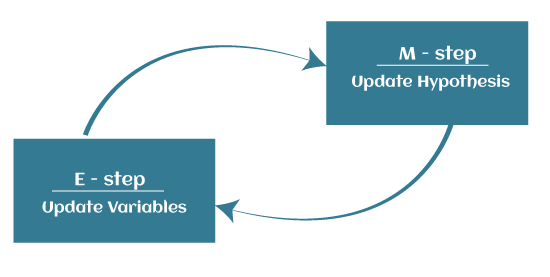
- Expectation step (E – step): It involves the estimation (guess) of all missing values in the dataset so that after completing this step, there should not be any missing value.
- Maximization step (M – step): This step involves the use of estimated data in the E-step and updating the parameters.
- Repeat E-step and M-step until the convergence of the values occurs.
The primary goal of the EM algorithm is to use the available observed data of the dataset to estimate the missing data of the latent variables and then use that data to update the values of the parameters in the M-step.
D. What are activation functions? Explain the Binary, Bipolar, Continuous, and Ramp activation functions.
Activation functions are mathematical functions applied to the output of each neuron in a neural network. They introduce non-linearity into the network, enabling it to learn complex patterns in the data. Here’s an explanation of the Binary, Bipolar, Continuous, and Ramp activation functions:
- Binary Activation Function:
- The binary activation function outputs either 0 or 1 based on a threshold. If the input is below the threshold, it outputs 0; if it’s equal to or above the threshold, it outputs 1.
- Mathematically:
[ f(x) = \begin{cases} 0 & \text{if } x < \text{threshold} \ 1 & \text{if } x \geq \text{threshold} \end{cases} ] - This function is typically used in binary classification tasks where the output should represent one of two classes.
- Bipolar Activation Function:
- The bipolar activation function outputs either -1 or 1 based on a threshold. If the input is below the threshold, it outputs -1; if it’s equal to or above the threshold, it outputs 1.
- Mathematically:
[ f(x) = \begin{cases} -1 & \text{if } x < \text{threshold} \ 1 & \text{if } x \geq \text{threshold} \end{cases} ] - Similar to the binary activation function, but it allows for representation of negative values.
- Continuous Activation Function:
- The continuous activation function produces a smooth, continuous output over the entire range of inputs. Examples include sigmoid and hyperbolic tangent (tanh) functions.
- Sigmoid function: [ f(x) = \frac{1}{1 + e^{-x}} ]
- Tanh function: [ f(x) = \frac{e^x – e^{-x}}{e^x + e^{-x}} ]
- These functions are commonly used in hidden layers of neural networks for their smoothness and suitability for gradient-based optimization algorithms like backpropagation.
- Ramp Activation Function:
- The ramp activation function linearly increases the output as the input increases up to a certain threshold, after which it saturates to a constant value.
- Mathematically:
[ f(x) = \begin{cases} x & \text{if } x < \text{threshold} \ \text{constant} & \text{if } x \geq \text{threshold} \end{cases} ] - This function can be useful in situations where the network needs to gradually activate neurons based on input strength, such as in certain types of regression tasks.
These activation functions serve different purposes and are chosen based on the requirements of the neural network architecture and the nature of the problem being solved.
Q.4
A. Write a short note on (a) Multivariate Regression and (b) Regularized Regression. [10]
Multivariate Regression:
Multivariate regression is an extension of simple linear regression that involves predicting a dependent variable based on multiple independent variables. In simple linear regression, there is only one independent variable, whereas in multivariate regression, there are multiple independent variables. The general form of multivariate regression can be represented as:
[ Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \ldots + \beta_nX_n + \varepsilon ]
Where:
- ( Y ) is the dependent variable.
- ( X_1, X_2, \ldots, X_n ) are the independent variables.
- ( \beta_0, \beta_1, \beta_2, \ldots, \beta_n ) are the regression coefficients.
- ( \varepsilon ) represents the error term.
Multivariate regression aims to estimate the values of the regression coefficients that minimize the sum of squared differences between the observed and predicted values of the dependent variable. This estimation is typically done using techniques such as ordinary least squares (OLS) or gradient descent.
Multivariate regression is widely used in various fields, including economics, finance, social sciences, and engineering, to analyze the relationship between multiple variables and make predictions or infer causal relationships.
Regularized Regression:
Regularized regression is a technique used to mitigate overfitting in regression models by adding a penalty term to the loss function. The penalty term discourages the model from learning complex relationships in the training data that may not generalize well to unseen data. There are two common types of regularized regression:
- Ridge Regression (L2 Regularization): In ridge regression, the penalty term is the squared sum of the magnitudes of the regression coefficients multiplied by a regularization parameter ( \lambda ). The objective function for ridge regression is to minimize the sum of squared errors plus the regularization term:
[ \text{Loss} = \sum_{i=1}^{n} (y_i – \hat{y}i)^2 + \lambda \sum{j=1}^{p} \beta_j^2 ]
Ridge regression shrinks the coefficients towards zero, but they never reach exactly zero, making it suitable for situations where all features are potentially relevant.
- Lasso Regression (L1 Regularization): In lasso regression, the penalty term is the sum of the absolute values of the regression coefficients multiplied by a regularization parameter ( \lambda ). The objective function for lasso regression is to minimize the sum of squared errors plus the regularization term:
[ \text{Loss} = \sum_{i=1}^{n} (y_i – \hat{y}i)^2 + \lambda \sum{j=1}^{p} |\beta_j| ]
Lasso regression not only shrinks the coefficients but can also set some coefficients exactly to zero, effectively performing feature selection by eliminating less important variables.
Regularized regression techniques are particularly useful when dealing with high-dimensional data or when the number of features exceeds the number of samples, as they help prevent overfitting and improve the generalization performance of the model.
B. What is the curse of dimensionality? Explain the PCA dimensionality reduction technique in detail. [10]
Handling the high-dimensional data is very difficult in practice, commonly known as the curse of dimensionality. If the dimensionality of the input dataset increases, any machine learning algorithm and model becomes more complex. As the number of features increases, the number of samples also gets increased proportionally, and the chance of overfitting also increases. If the machine learning model is trained on high-dimensional data, it becomes overfitted and results in poor performance.
Hence, it is often required to reduce the number of features, which can be done with dimensionality reduction.
Principal Component Analysis is an unsupervised learning algorithm that is used for the dimensionality reduction in machine learning. It is a statistical process that converts the observations of correlated features into a set of linearly uncorrelated features with the help of orthogonal transformation. These new transformed features are called the Principal Components. It is one of the popular tools that is used for exploratory data analysis and predictive modeling. It is a technique to draw strong patterns from the given dataset by reducing the variances.
PCA generally tries to find the lower-dimensional surface to project the high-dimensional data.
PCA works by considering the variance of each attribute because the high attribute shows the good split between the classes, and hence it reduces the dimensionality. Some real-world applications of PCA are image processing, movie recommendation system, optimizing the power allocation in various communication channels. It is a feature extraction technique, so it contains the important variables and drops the least important variable.
The PCA algorithm is based on some mathematical concepts such as:
- Variance and Covariance
- Eigenvalues and Eigen factors
Steps for PCA algorithm
- Getting the dataset
Firstly, we need to take the input dataset and divide it into two subparts X and Y, where X is the training set, and Y is the validation set. - Representing data into a structure
Now we will represent our dataset into a structure. Such as we will represent the two-dimensional matrix of independent variable X. Here each row corresponds to the data items, and the column corresponds to the Features. The number of columns is the dimensions of the dataset. - Standardizing the data
In this step, we will standardize our dataset. Such as in a particular column, the features with high variance are more important compared to the features with lower variance.
If the importance of features is independent of the variance of the feature, then we will divide each data item in a column with the standard deviation of the column. Here we will name the matrix as Z. - Calculating the Covariance of Z
To calculate the covariance of Z, we will take the matrix Z, and will transpose it. After transpose, we will multiply it by Z. The output matrix will be the Covariance matrix of Z. - Calculating the Eigen Values and Eigen Vectors
Now we need to calculate the eigenvalues and eigenvectors for the resultant covariance matrix Z. Eigenvectors or the covariance matrix are the directions of the axes with high information. And the coefficients of these eigenvectors are defined as the eigenvalues. - Sorting the Eigen Vectors
In this step, we will take all the eigenvalues and will sort them in decreasing order, which means from largest to smallest. And simultaneously sort the eigenvectors accordingly in matrix P of eigenvalues. The resultant matrix will be named as P*. - Calculating the new features Or Principal Components
Here we will calculate the new features. To do this, we will multiply the P* matrix to the Z. In the resultant matrix Z*, each observation is the linear combination of original features. Each column of the Z* matrix is independent of each other. - Remove less or unimportant features from the new dataset.
The new feature set has occurred, so we will decide here what to keep and what to remove. It means, we will only keep the relevant or important features in the new dataset, and unimportant features will be removed out.
Applications of Principal Component Analysis
- PCA is mainly used as the dimensionality reduction technique in various AI applications such as computer vision, image compression, etc.
- It can also be used for finding hidden patterns if data has high dimensions. Some fields where PCA is used are Finance, data mining, Psychology, etc.
Q.5
A. Design a Hebb net to implement the OR function (consider bipolar inputs and targets). [10]


B. Draw the Delta Learning Rule (LMS-Widrow Hoff) model and explain it with a training process flowchart. [10]
Answer : https://www.doubtly.in/q/draw-delta-learning-rule-lms-widrow-hoff-model/
Q.6 Write short notes on any FOUR
A. Least Square Regression for classification [05]
Answer : https://www.doubtly.in/q/square-regression-classification/
B. Differentiate between Ridge and Lasso Regression [05]
| Ridge Regression | Lasso Regression |
|---|---|
| Shrinks the coefficients toward zero | Encourages some coefficients to be exactly zero |
| Adds a penalty term proportional to the sum of squared coefficients | Adds a penalty term proportional to the sum of absolute values of coefficients |
| Does not eliminate any features | Can eliminate some features |
| Suitable when all features are importantly | Suitable when some features are irrelevant or redundant |
| More computationally efficient | Less computationally efficient |
| Requires setting a hyperparameter | Requires setting a hyperparameter |
| Performs better when there are many small to medium-sized coefficients | Performs better when there are a few large coefficients |
C. Artificial Neural Network [05]
An Artificial Neural Network in the field of Artificial intelligence where it attempts to mimic the network of neurons makes up a human brain so that computers will have an option to understand things and make decisions in a human-like manner. The artificial neural network is designed by programming computers to behave simply like interconnected brain cells.
There are around 1000 billion neurons in the human brain. Each neuron has an association point somewhere in the range of 1,000 and 100,000. In the human brain, data is stored in such a manner as to be distributed, and we can extract more than one piece of this data when necessary from our memory parallelly. We can say that the human brain is made up of incredibly amazing parallel processors.
We can understand the artificial neural network with an example, consider an example of a digital logic gate that takes an input and gives an output. “OR” gate, which takes two inputs. If one or both the inputs are “On,” then we get “On” in output. If both the inputs are “Off,” then we get “Off” in output. Here the output depends upon input. Our brain does not perform the same task. The outputs to inputs relationship keep changing because of the neurons in our brain, which are “learning.”
The architecture of an artificial neural network:
To understand the concept of the architecture of an artificial neural network, we have to understand what a neural network consists of. In order to define a neural network that consists of a large number of artificial neurons, which are termed units arranged in a sequence of layers. Lets us look at various types of layers available in an artificial neural network.
Artificial Neural Network primarily consists of three layers:
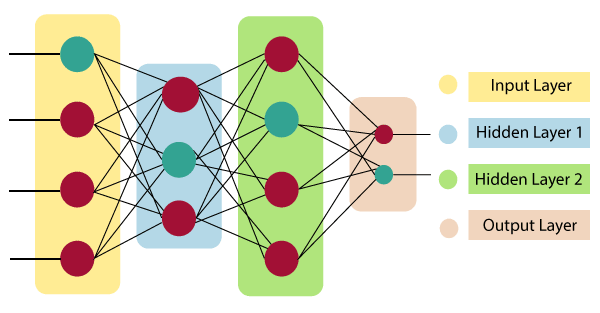
Input Layer:
As the name suggests, it accepts inputs in several different formats provided by the programmer.
Hidden Layer:
The hidden layer presents in-between input and output layers. It performs all the calculations to find hidden features and patterns.
Output Layer:
The input goes through a series of transformations using the hidden layer, which finally results in output that is conveyed using this layer.
The artificial neural network takes input and computes the weighted sum of the inputs and includes a bias. This computation is represented in the form of a transfer function.
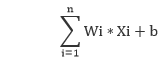
It determines weighted total is passed as an input to an activation function to produce the output. Activation functions choose whether a node should fire or not. Only those who are fired make it to the output layer. There are distinctive activation functions available that can be applied upon the sort of task we are performing.
D. Feature selection methods for dimensionality reduction [05]
Feature selection is the process of selecting a subset of the relevant features and excluding the irrelevant features present in a dataset to build a model of high accuracy. In other words, it is a way of choosing the optimal features from the input dataset.
In feature selection, we aim to find k out of the total n features that provide the most information, discarding the remaining (n−k) dimensions. Subset selection is one method used for feature selection.
Three methods are commonly used for feature selection:
- Filter Methods
- Wrapper Methods
- Embedded Methods
Example:
Suppose we are constructing a model to predict the height of a building. We have a dataset with various features, including the number of windows, number of apartments, and color of the building.
In this dimensionality reduction example, the feature of color is unlikely to be a decisive factor in the height of a building. Therefore, we can remove or deselect this feature to simplify our dataset.
E. Perceptron Neural Network [05]
Perceptron is one of the simplest Artificial neural network architectures. It was introduced by Frank Rosenblatt in 1957s. It is the simplest type of feedforward neural network, consisting of a single layer of input nodes that are fully connected to a layer of output nodes. It can learn the linearly separable patterns. it uses slightly different types of artificial neurons known as threshold logic units (TLU). it was first introduced by McCulloch and Walter Pitts in the 1940s.
Types of Perceptron
- Single-Layer Perceptron: This type of perceptron is limited to learning linearly separable patterns. effective for tasks where the data can be divided into distinct categories through a straight line.
- Multilayer Perceptron: Multilayer perceptrons possess enhanced processing capabilities as they consist of two or more layers, adept at handling more complex patterns and relationships within the data.
Basic Components of Perceptron
A perceptron, the basic unit of a neural network, comprises essential components that collaborate in information processing.
- Input Features: The perceptron takes multiple input features, each input feature represents a characteristic or attribute of the input data.
- Weights: Each input feature is associated with a weight, determining the significance of each input feature in influencing the perceptron’s output. During training, these weights are adjusted to learn the optimal values.
- Summation Function: The perceptron calculates the weighted sum of its inputs using the summation function. The summation function combines the inputs with their respective weights to produce a weighted sum.
- Activation Function: The weighted sum is then passed through an activation function. Perceptron uses Heaviside step function functions. which take the summed values as input and compare with the threshold and provide the output as 0 or 1.
- Output: The final output of the perceptron, is determined by the activation function’s result. For example, in binary classification problems, the output might represent a predicted class (0 or 1).
- Bias: A bias term is often included in the perceptron model. The bias allows the model to make adjustments that are independent of the input. It is an additional parameter that is learned during training.
- Learning Algorithm (Weight Update Rule): During training, the perceptron learns by adjusting its weights and bias based on a learning algorithm. A common approach is the perceptron learning algorithm, which updates weights based on the difference between the predicted output and the true output.
