Artificial Intelligence Question paper Solutions (AI-DS/AI-ML/CSE(DS/AIML))
Table of Contents
Q1 ) Question paper
A. What is PEAS descriptor? Give PEAS descriptor for robot maid for cleaning the house.
PEAS stands for Performance measure, Environment, Actuators, and Sensors. It is a framework used in the field of artificial intelligence (AI) to describe and analyze intelligent agent systems. Each letter in PEAS corresponds to a different aspect of the system:
- Performance Measure: This defines how the success of the system will be measured. It specifies the criteria or metrics that determine the effectiveness of the intelligent agent in achieving its goals.
- Environment: This describes the external context or surroundings in which the intelligent agent operates. The environment includes everything that is not part of the agent but can be affected by the agent’s actions.
- Actuators: Actuators are the components of the agent that carry out the actions or execute the strategies decided upon by the agent. These actions are intended to affect the environment in some way.
- Sensors: Sensors are the components that allow the agent to perceive or receive information from the environment. They provide the agent with the necessary input to make informed decisions and take appropriate actions.
PEAS descriptor for robot maid for cleaning the house.
| Component | Description |
|---|---|
| Performance Measure | Efficiency in cleaning, time taken to complete tasks, cleanliness achieved, ability to adapt to different types of surfaces, and user satisfaction with the cleaning results. |
| Environment | Indoor household environment, which includes various rooms, furniture, floors, carpets, and potentially obstacles or objects that the robot may encounter during cleaning tasks. |
| Actuators | Cleaning tools such as brushes, vacuuming mechanism, mopping mechanism, and mobility systems for navigation around the house. |
| Sensors | Cameras, infrared sensors, and pressure sensors for navigation, object detection, and avoidance. Dirt sensors to detect dirty areas. |
B. Discuss different applications of AI.
Here are 10 major applications of artificial intelligence:
- Virtual Assistants – Siri, Alexa, Google Assistant etc. that understand voices and languages to answer questions and perform tasks.
- Recommendation Systems – Netflix, Amazon etc. use AI to study customer behavior and recommend products and content.
- Computer Vision – Facial recognition, image classification, object detection for surveillance, self-driving cars, photo organizing.
- Natural Language Processing – Chatbots, sentiment analysis, text summarization, language translation, conversational AI.
- Predictive Analytics – Detect patterns in data to make predictions about future events and outcomes in areas like predictive maintenance, healthcare, etc.
- Autonomous Vehicles – AI allows self-driving cars to perceive environment, detect objects, signs, pedestrians and navigate without human intervention.
- Robotics – AI makes industrial and service robots smarter, more perceptive, versatile and collaborative to improve business efficiency.
- Fraud Prevention – Real-time fraud detection in credit cards, healthcare, insurance by analyzing data patterns and user behavior.
- Medical Diagnosis – AI assists doctors in diagnosing diseases, treatment planning through synthesis of patient records and medical data.
- Personalization – AI analyzes customer history and behavior to provide tailored recommendations and personalization across shopping, content platforms, marketing campaigns etc.
C. Draw and explain architecture of Expert System.
An expert system is a computer program that is designed to solve complex problems and to provide decision-making ability like a human expert. It performs this by extracting knowledge from its knowledge base using the reasoning and inference rules according to the user queries.
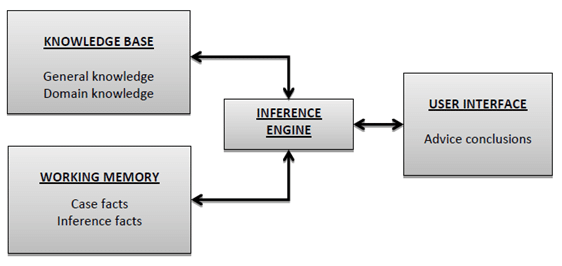
- User Interface (UI):
- This is the front end of the expert system that interacts with the user.
- It provides a way for users to input information and receive output from the system.
- The UI can take various forms, such as a graphical user interface (GUI) or a command-line interface (CLI), depending on the application.
- Knowledge Base (KB):
- The knowledge base is a central component of the expert system that stores information about the domain.
- It includes two main components: facts and rules.
- Facts: These are pieces of information about the specific case or domain. Facts are typically represented in the form of statements.
- Rules: These are logical statements that define relationships between various facts. Rules are used by the inference engine to make decisions.
- Inference Engine:
- The inference engine is responsible for drawing conclusions based on the information stored in the knowledge base.
- It uses various reasoning strategies, such as forward chaining (data-driven) or backward chaining (goal-driven), to infer new facts or make decisions.
- The inference engine interprets the rules and applies them to the given set of facts to derive new conclusions.
- Working Memory:
- Working memory is a temporary storage area where the current set of facts and conclusions are kept during the inference process.
- It is used by the inference engine to manipulate and update information as it processes the rules.
D. In a class, there are 80% of the students who like English and 30% of the students who likes English and Mathematics, and then what is the percentage of students those who like Math, also like English? Solve it using Conditional probability.
https://www.doubtly.in/10957/class-there-students-like-english-students-likes-english-mathematics
Q2
A. Define chromosome, selection, fitness function, cross over and mutation as used in Genetic Algorithm. Explain how Genetic Algorithm in works.
B. Draw and describe the architecture of Utility based agent . How is it different from Model based agent ?
The agents which are developed having their end uses as building blocks are called utility-based agents. When there are multiple possible alternatives, then to decide which one is best, utility-based agents are used. They choose actions based on a preference (utility) for each state. Sometimes achieving the desired goal is not enough. We may look for a quicker, safer, cheaper trip to reach a destination. Agent happiness should be taken into consideration. Utility describes how “happy” the agent is. Because of the uncertainty in the world, a utility agent chooses the action that maximizes the expected utility. A utility function maps a state onto a real number which describes the associated degree of happiness.
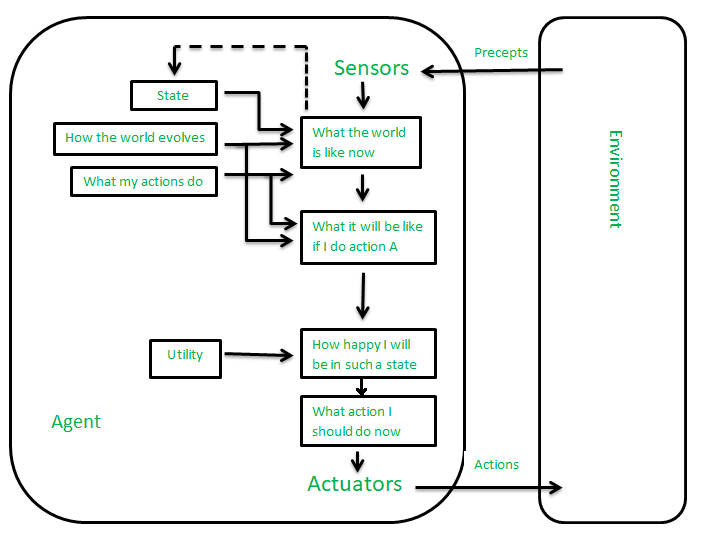
Differnces
Utility-Based Agent:
- Decisions based on maximizing expected utility.
- Uses a utility function to represent preferences.
- No explicit model of the environment.
- Flexibility in adapting to different environments.
- Decision-making without detailed understanding of the world.
Model-Based Agent:
- Decisions rely on simulating the environment through an internal model.
- Maintains an explicit internal model of the environment.
- Requires modifications to the model for adaptation.
- Provides a detailed understanding of the environment.
- Decision-making involves explicit reasoning about the world state.
Q3
A. Explain A* algorithm in detail.
B. Define belief Network. Describe the steps of constructing belief network with an example.
https://www.javatpoint.com/bayesian-belief-network-in-artificial-intelligence
Belief Network:
A belief network, also known as a Bayesian network or probabilistic graphical model, is a graphical representation of probabilistic relationships among a set of variables. It uses a directed acyclic graph (DAG) to model the dependencies between variables along with conditional probability tables (CPTs) associated with each variable. Belief networks are used for reasoning under uncertainty and are widely applied in fields such as artificial intelligence, machine learning, and decision support systems.
Steps of Constructing a Belief Network:
Constructing a belief network involves the following steps:
- Identify Variables:
- Identify the variables relevant to the problem domain. These variables should represent key aspects or entities in the system.
- Define Dependencies:
- Determine the dependencies between variables. Identify which variables influence or depend on others. This step involves understanding the causal relationships or dependencies in the system.
- Graphical Representation:
- Represent the identified dependencies using a directed acyclic graph (DAG). In a DAG, nodes represent variables, and directed edges indicate the direction of influence or dependence between variables.
- Assign Conditional Probability Tables (CPTs):
- For each variable in the graph, define the conditional probability table (CPT). The CPT specifies the probability distribution of a variable given its parents in the graph.
- Check for Consistency:
- Ensure that the constructed belief network is consistent with the dependencies and conditional probability distributions. The probabilities for each variable should sum to 1, and the network should accurately reflect the relationships in the system.
Example: Constructing a Belief Network for a Medical Diagnosis Problem:
Consider a medical diagnosis problem with three variables: Symptoms, Disease, and Test Result. The goal is to construct a belief network to model the relationships between these variables.
- Identify Variables:
- Variables: Symptoms, Disease, Test Result
- Define Dependencies:
- Symptoms influence the likelihood of having a disease.
- The disease affects the test results.
- Test results are also influenced by other factors (e.g., the accuracy of the test).
- Graphical Representation:
- Construct a DAG with nodes representing Symptoms, Disease, and Test Result. Use directed edges to represent the dependencies.
Symptoms --> Disease Disease --> Test Result - Assign Conditional Probability Tables (CPTs):
- Define the conditional probability distributions for each variable given its parents. For example:
- P(Disease | Symptoms)
- P(Test Result | Disease)
- Define the conditional probability distributions for each variable given its parents. For example:
- Check for Consistency:
- Ensure that the probabilities in the CPTs are consistent, and the belief network accurately reflects the dependencies and relationships in the medical diagnosis problem.
Q4
A. Illustrate forward chaining and backward chaining in propositional logic with example.
Forward Chaining:
Forward chaining, also known as data-driven reasoning, is a reasoning method that starts with the known facts and uses inference rules to derive new conclusions until the goal is reached. It is commonly used in rule-based systems.
Let’s consider a set of rules in propositional logic:
- Rule 1: If it is raining, then the grass is wet. (Rain → Wet)
- Rule 2: If the grass is wet, then the sprinkler was on. (Wet → Sprinkler)
- Rule 3: It is raining. (Rain)
Let’s apply forward chaining:
- Initial State:
- Known facts: {Rain}
- Apply Rules:
- Rule 1: Rain → Wet (Apply)
- New facts: {Rain, Wet}
- Rule 2: Wet → Sprinkler (Apply)
- New facts: {Rain, Wet, Sprinkler}
- Goal Reached:
- The goal of determining if the sprinkler was on is reached.
Forward chaining starts with the known facts (initial state) and applies rules to derive new facts until the goal is achieved.
Backward Chaining:
Backward chaining, also known as goal-driven reasoning, starts with the goal and works backward to determine whether the known facts support the goal. It involves using inference rules in reverse order.
Let’s consider the same set of rules:
- Rule 1: If it is raining, then the grass is wet. (Rain → Wet)
- Rule 2: If the grass is wet, then the sprinkler was on. (Wet → Sprinkler)
- Rule 3: It is raining. (Rain)
Let’s apply backward chaining:
- Goal:
- Goal: Is the sprinkler on?
- Apply Rules (Backward):
- Rule 2: Wet → Sprinkler (Apply)
- Subgoal: Is the grass wet?
- Rule 1: Rain → Wet (Apply)
- Subgoal: Is it raining?
- Rule 3: It is raining. (Apply)
- Goal reached: The grass is wet.
- Goal reached: The sprinkler is on.
- Rule 2: Wet → Sprinkler (Apply)
Backward chaining starts with the goal and works backward, using inference rules to check whether the known facts support the goal.
B. Explain different types of learning in AI.
- Supervised Learning:
- Definition: Supervised learning involves training a model on a labeled dataset, where each input is associated with a corresponding output or target. The goal is for the algorithm to learn a mapping from inputs to outputs.
- Example: Classifying emails as spam or not spam based on labeled training data.
- Unsupervised Learning:
- Definition: Unsupervised learning involves training a model on an unlabeled dataset, and the algorithm must discover patterns or relationships within the data without explicit guidance.
- Example: Clustering similar documents together without prior knowledge of document categories.
- Semi-Supervised Learning:
- Definition: Semi-supervised learning uses a combination of labeled and unlabeled data for training. It leverages the labeled data for supervised learning and the unlabeled data to improve the model’s understanding of the underlying structure of the data.
- Example: Training a speech recognition system with a small set of labeled audio samples and a larger set of unlabeled audio samples.
- Reinforcement Learning:
- Definition: Reinforcement learning involves an agent interacting with an environment and learning to make decisions by receiving feedback in the form of rewards or punishments. The agent’s goal is to learn a policy that maximizes the cumulative reward over time.
- Example: Training an autonomous vehicle to navigate a city by rewarding it for safe and efficient driving.
- Ensemble Learning:
- Definition: Ensemble learning involves combining the predictions of multiple models (learners) to improve overall performance. The idea is that combining diverse models can lead to better results than individual models.
- Example: Random Forest, which aggregates the predictions of multiple decision trees, each trained on a different subset of the data.
Q5
A. Consider the following axioms All people who are graduating are happy. All happy people smile. Someone is graduating. Prove that “Is someone Smiling?” using resolution technique. Draw resolution tree.
https://www.doubtly.in/10973/consider-following-axioms-people-graduating-people-someone-graduating
B. Explain Alpha-beta pruning algorithm. Apply alpha beta pruning on following example considering first node as MAX.
- Alpha-beta pruning is a modified version of the minimax algorithm. It is an optimization technique for the minimax algorithm.
- As we have seen in the minimax search algorithm that the number of game states it has to examine are exponential in depth of the tree. Since we cannot eliminate the exponent, but we can cut it to half. Hence there is a technique by which without checking each node of the game tree we can compute the correct minimax decision, and this technique is called pruning. This involves two threshold parameter Alpha and beta for future expansion, so it is called alpha-beta pruning. It is also called as Alpha-Beta Algorithm.
- Alpha-beta pruning can be applied at any depth of a tree, and sometimes it not only prune the tree leaves but also entire sub-tree.
- The two-parameter can be defined as:
- Alpha: The best (highest-value) choice we have found so far at any point along the path of Maximizer. The initial value of alpha is -∞.
- Beta: The best (lowest-value) choice we have found so far at any point along the path of Minimizer. The initial value of beta is +∞.
- The Alpha-beta pruning to a standard minimax algorithm returns the same move as the standard algorithm does, but it removes all the nodes which are not really affecting the final decision but making algorithm slow. Hence by pruning these nodes, it makes the algorithm fast.
https://www.javatpoint.com/ai-alpha-beta-pruning
Q.6
A. Explain hill climbing algorithm with example. Explain the problems faced by hill climbing algorithm.
- Hill climbing algorithm is a local search algorithm which continuously moves in the direction of increasing elevation/value to find the peak of the mountain or best solution to the problem. It terminates when it reaches a peak value where no neighbor has a higher value.
- Hill climbing algorithm is a technique which is used for optimizing the mathematical problems. One of the widely discussed examples of Hill climbing algorithm is Traveling-salesman Problem in which we need to minimize the distance traveled by the salesman.
- It is also called greedy local search as it only looks to its good immediate neighbor state and not beyond that.
- A node of hill climbing algorithm has two components which are state and value.
- Hill Climbing is mostly used when a good heuristic is available.
- In this algorithm, we don’t need to maintain and handle the search tree or graph as it only keeps a single current state.
Problems in different regions in Hill climbing
Hill climbing cannot reach the optimal/best state(global maximum) if it enters any of the following regions :
- Local maximum: At a local maximum all neighboring states have a value that is worse than the current state. Since hill-climbing uses a greedy approach, it will not move to the worse state and terminate itself. The process will end even though a better solution may exist.
To overcome the local maximum problem: Utilize the backtracking technique. Maintain a list of visited states. If the search reaches an undesirable state, it can backtrack to the previous configuration and explore a new path. - Plateau: On the plateau, all neighbors have the same value. Hence, it is not possible to select the best direction.
To overcome plateaus: Make a big jump. Randomly select a state far away from the current state. Chances are that we will land in a non-plateau region. - Ridge: Any point on a ridge can look like a peak because movement in all possible directions is downward. Hence the algorithm stops when it reaches this state.
To overcome Ridge: In this kind of obstacle, use two or more rules before testing. It implies moving in several directions at once.
B. Explain total order planning and partial order planning in detail with example.
Total order planning and partial order planning are two different approaches to solving planning problems in the field of artificial intelligence and automated planning.
- Total Order Planning:
- In total order planning, the planner generates a linear sequence of actions that must be executed to achieve the goal.
- The actions are ordered from the beginning to the end, and the execution must follow this strict order.
- This approach assumes that the order in which actions are executed is critical and that certain actions must precede or follow others without any flexibility.
- Total order planning is more rigid but may be appropriate in situations where the order of actions is strictly enforced.
- Consider a simple task of making a cup of coffee with total order planning:
- Boil water
- Grind coffee beans
- Put coffee grounds in the filter
- Place the filter in the coffee maker
- Pour hot water into the coffee maker
- Turn on the coffee maker
- Wait for the coffee to brew
- Pour the brewed coffee into a cup
- Add sugar and milk (optional)
- Partial Order Planning:
- In partial order planning, the planner generates a set of actions with dependencies, but the specific order in which these actions are executed is not predetermined.
- This approach allows for more flexibility in the execution order, and actions can be interleaved as long as their dependencies are satisfied.
- Partial order planning is useful when the order of some actions is not critical, and the planner can explore different ways to achieve the goal.
- Continuing with the coffee example, a partial order plan might look like this:
- Action 1: Boil water
- Action 2: Grind coffee beans
- Action 3: Put coffee grounds in the filter
- Action 4: Place the filter in the coffee maker
- Action 5: Pour hot water into the coffee maker
- Action 6: Turn on the coffee maker
- Action 7: Wait for the coffee to brew
- Action 8: Pour the brewed coffee into a cup
- Action 9: Add sugar (optional)
- Action 10: Add milk (optional)